On November 6, 2024, the day after election day, several major news outlets confirmed that Donald Trump was elected as the next president of the United States (1). In light of this news, this blog reflects on the election prediction model that I made in the weeks leading up to the election, attempting to evaluate why I predicted the opposite outcome and what could be done to contribute to better modeling in future elections.
Recapping my Model
Model Type and Parameters
As discussed in my last blog post, my final election model was a regularized linear regression attempting to predict single-party Democratic vote share at the state level. To do so, I considered five total independent variables. This includes four state level factors (ie: varying by both state and election year)
- Democratic polling performance one week out from the election
- Democratic vote share in the last Presidential election
- Democratic vote share in the second to last Presidential election
- Score on the Cost of Voting Index
Furthermore, this includes one national level factor (ie: varying only by election year, meaning that all states within a certain election had the same value)
- An interaction term considering both the number of precedents the Supreme Court overturned and whether or not the Supreme Court has had a conservative shift in its rulings in the four years before the election
I trained this model using state-level data from each Presidential election after 1984 (aside from cases where data was missing, as discussed in greater depth in my last blog post). Following an initial training as a standard OLS linear regression model, I regularized the model using Elastic-Net (2)
Model Validation
While my ultimate model included the factors above, I decided on these specifications and shape after testing a total of 32 different models, which varied by the predictors included and the data that was used (I tested models trained on two different datasets – one that included all state-level Presidential election outcomes after 1984 and another that only included this data after the 1996 Presidential election). As a benchmark of performance, I evaluated how effectively each of these models predicted the vote share that Hillary Clinton received during the 2016 presidential election in each of the seven “battleground” states of the 2024 election (3).
Given that the model described above had the lowest absolute prediction error, I selected it as my prediction model for the election, before regularizing the model using Elastic-Net (2).
Model Estimation and Final Prediction
The coefficients of both the original OLS and regularized models are summarized in the first figure below. Additionally, the electoral outcomes that the regularized model predicted are shown in the following figures below. These are all also found in my previous blog post.
Coefficients of OLS and Regularized Models
| Coefficient | OLS | Elastic-Net |
|---|---|---|
| mean_1_wk_poll_support | 0.7837 | 0.7737 |
| D_pv_lag1 | 0.4170 | 0.4083 |
| D_pv_lag2 | -0.0987 | -0.0811 |
| InitialCOVI | 0.0444 | 0.0196 |
| sc_interact | 0.1792 | 0.1800 |
Predicted Outcomes in Swing States
| State | Predicted Vote Share - Harris | Predicted Vote Share - Trump | Winner |
|---|---|---|---|
| Arizona | 50.29389 | 45.99834 | DEM |
| Georgia | 50.52702 | 46.23711 | DEM |
| Michigan | 51.27286 | 43.88791 | DEM |
| Nevada | 50.68964 | 43.00990 | DEM |
| North Carolina | 50.12645 | 46.23600 | DEM |
| Pennsylvania | 51.00805 | 45.05850 | DEM |
| Wisconsin | 51.07005 | 46.00051 | DEM |
Predicted Electoral Outcomes (Excluding States Without Polling Data)
| Harris | Trump |
|---|---|
| 271 | 77 |
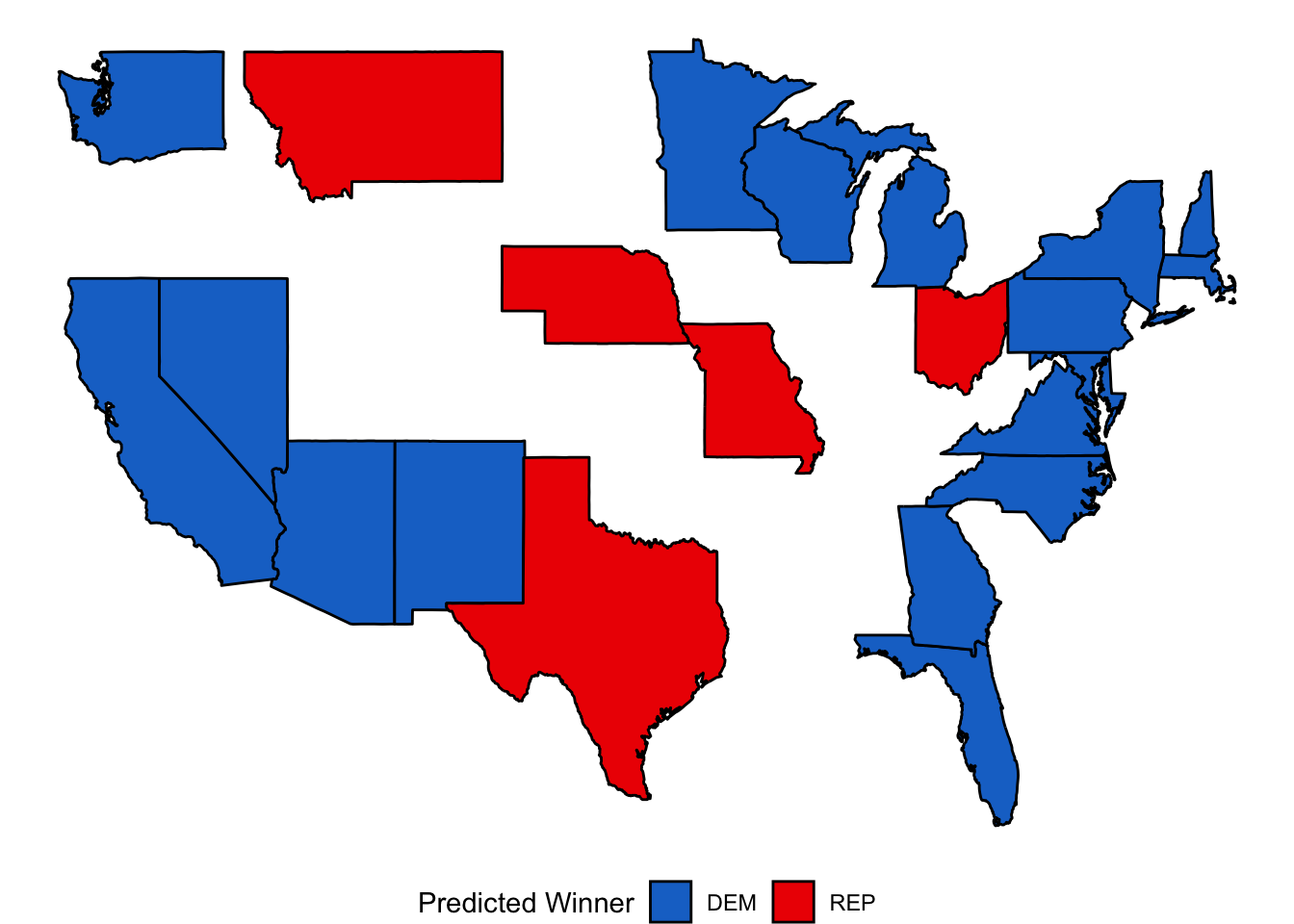
Predicted Winners by State (excluding states without polling data)
(Thank you to Matt for the starter code!)
Trends in Model Accuracy
My model demonstrates a strong performance for Democrats everywhere, including in a state that was largely predicted to vote Republican even prior to the election based on the polls (although my model predicted this result only by a small margin) (3). This suggests that the other variables I included in my model might be positively skewing Democratic performance. To explore this further, I calculated the Mean Absolute Error of each prediction type and ranked states based on how well my model predicted their Democratic and Republican vote shares.
| Dem. Mean AE | Rep. Mean AE |
|---|---|
| 3.301153 | 5.471356 |
Top 10 States with Most Accurate Harris Predictions
| State | Prediction Error (Prediction-Actual) |
|---|---|
| Nebraska | 1.975401 |
| Georgia | 2.010816 |
| Virginia | 2.239677 |
| Ohio | 2.250282 |
| Washington | 2.300059 |
| Wisconsin | 2.368400 |
| Pennsylvania | 2.496831 |
| New Mexico | 2.532170 |
| North Carolina | 2.546915 |
| Montana | 2.748772 |
Top 10 States with Most Accurate Trump Predictions
| State | Prediction Error (Prediction-Actual) |
|---|---|
| Montana | -3.051312 |
| Wisconsin | -3.622334 |
| New Mexico | -4.026311 |
| Nebraska | -4.047265 |
| Washington | -4.132367 |
| New Hampshire | -4.364353 |
| Minnesota | -4.484310 |
| Georgia | -4.505574 |
| Missouri | -4.631653 |
| North Carolina | -4.695081 |
Battleground States by Democratic Prediction Error
| State | Prediction Error (Prediction-Actual) |
|---|---|
| Georgia | 2.010816 |
| Wisconsin | 2.368400 |
| Pennsylvania | 2.496831 |
| North Carolina | 2.546915 |
| Michigan | 2.924274 |
| Nevada | 3.237941 |
| Arizona | 3.633383 |
Battleground States by Republican Prediction Error
| State | Prediction Error (Prediction-Actual) |
|---|---|
| Wisconsin | -3.622334 |
| Georgia | -4.505574 |
| North Carolina | -4.695081 |
| Pennsylvania | -5.468451 |
| Michigan | -5.830561 |
| Arizona | -6.297690 |
| Nevada | -7.623095 |
This analysis demonstrates that my model generally did better at predicting Democratic vote shares than Republican vote shares, with the magnitude of the prediction error generally being lower for the Democratic outcomes. In particular, the mean absolute error for Democratic vote share was 3.30, while that for Republican vote share was 5.47. However, my model consistently both overpredicted Democratic performance and underpredicted Republican performance, leading to large prediction errors when trying to predict state winners.
Interestingly, this analysis suggests that the model also did a better job at predicting Democratic vote share than Republican vote share in the seven swing states (3). In terms of raw numbers, the absolute prediction error of the best Republican prediction is larger than six out of the seven Democratic prediction errors, indicating that the Democratic model clearly had better performance. However, when also considering all of the other states, it seems like the model did a slightly better job at predicting the battleground states’ Democratic turnout, with four out of the seven appearing in the top 10 Democratic predictions and only three out of the seven appearing in the top 10 Republican predictions.
To understand geographic trends further, I charted my model’s performance on both metrics.
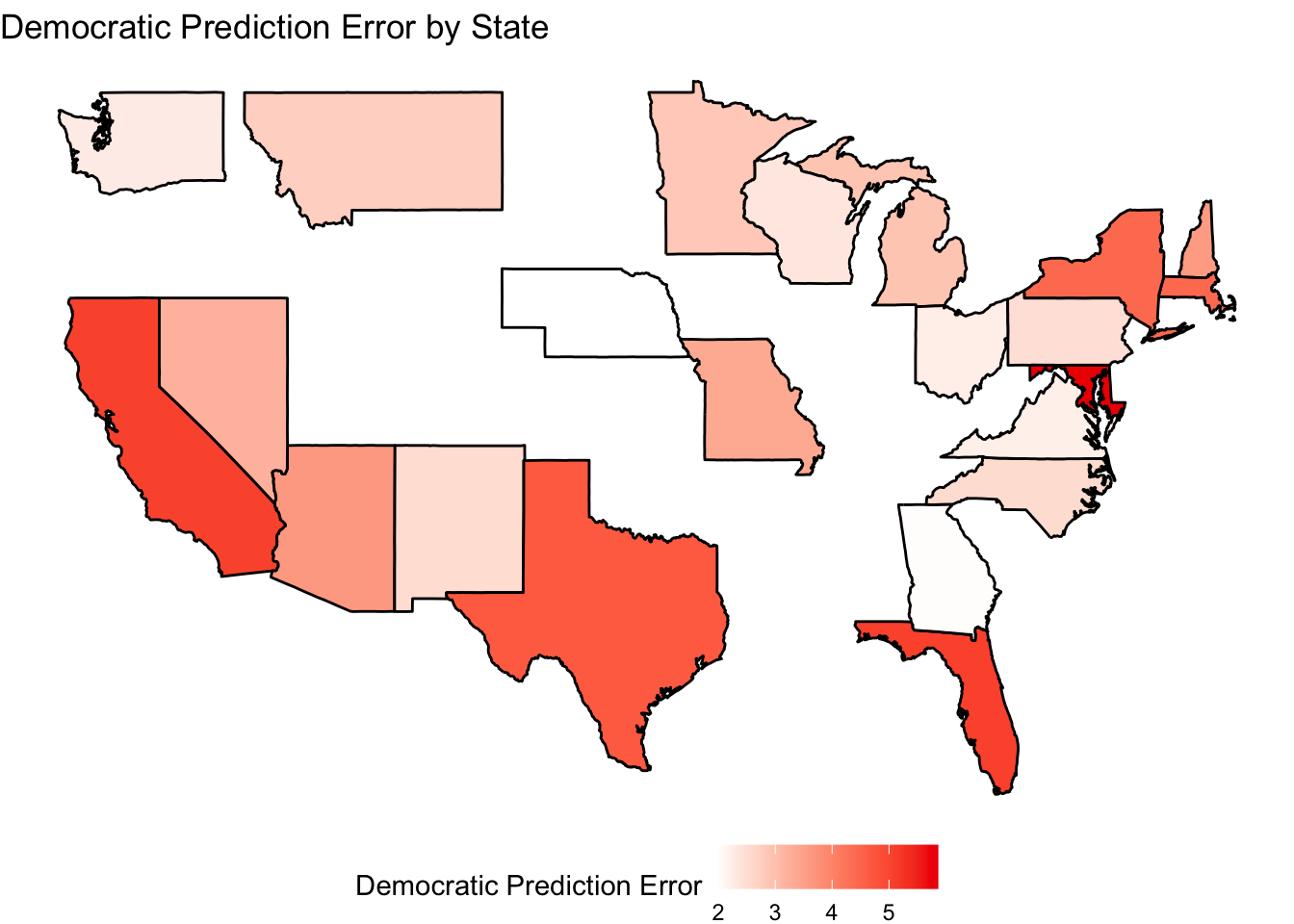
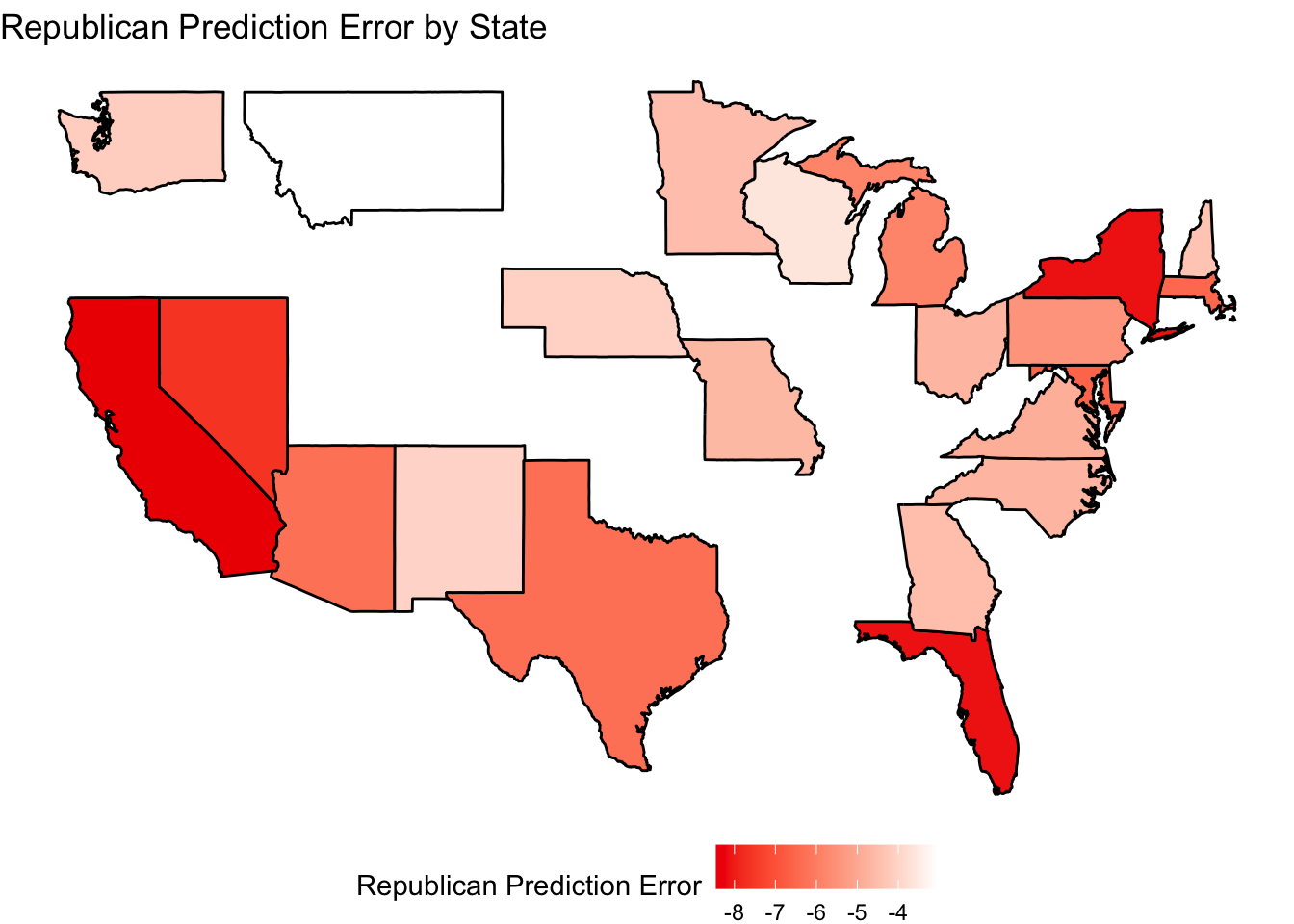
These maps seem to demonstrate that my models were especially inaccurate in states that were not deemed swing states in the 2024 election, such as California, Florida, Texas, Maryland, Massachusetts, and New York. This is likely because I selected my model based on its performance in predicting outcomes in the seven 2024 swing states (3).
Nevertheless, it is interesting to note that my model had greater prediction errors in some swing states than others. For example, we see from both the visual analysis and the tables above that the model had worse prediction errors in Arizona and Nevada (the bottom two battleground states in terms of both Democratic and Republican prediction errors) than Wisconsin and Georgia.
Hypotheses
There are several reasons why I believe my models were so inaccurate.
Model Parameters
When considering my model parameters, an immediate hypothesis that I have is that my model was too reliant on polling data. As discussed in our last course section, though polling data may produce models that seem to perform better, their potential to be imprecise measures may mean that they could easily limit model performance.
Similarly, I am not sure that the Cost of Voting Index measurements closely reflected the electoral situation that existed in this upcoming election. With election laws changing rather often, it’s not clear that the metrics I used accurately reflected the true Cost of Voting that voters faced (8).
Finally, I think part of my Republican prediction error may have resulted from my choice to predict Republican vote share using two measures of lagged Democratic vote share and Democratic poll numbers. Given that I was not predicting two-party vote share, it’s very likely that the Democratic vote share/poll values may not have been a great predictor of a somewhat independent measure of Republican vote share (not entirely independent, but not a complement as it would be if I had used two-party vote share).
Validation Methods
However, I think the bigger issue with my study may have been my validation method, which assumed that this election would be largely similar to the 2016 election. For one, my assumption partially relied on the fact that the US economy was growing at similar rates prior to both elections, but I did not consider an incredibly salient economic variable in the minds of many voters – inflation (9). Though inflation was only at about 1.6% in October 2016, inflation was at a significantly higher 2.6% in October 2024 – a figure that also followed years of above average inflation (10). This, combined with Obama’s relative popularity at the end of his term compared to Biden’s popularity, may have weakened my ability to compare the two elections, even if both resulted in a Democratic loss (11). In other words, though my initial ideas of how to build my model were based on the precedent of simplicity and reliance on the fundamentals of economic performance and approval, as described in Alan Abramowitz’s Time for Change model, my final choice in validation did not do well at approximating these underlying factors.
Ultimately, using this flawed method also likely exacerbated issues of omitted variable bias that may have plagued my model. A strong example of this is my exclusion of inflation. While I initially considered the economic variables of GDP growth and unemployment because of the example of Time for Change and a belief that unemployment was a salient issue because it directly impacts voters’ livelihoods, considering the role of inflation likely would have substantially changed my model (12). However, even putting aside variables that I did not consider from the beginning, this validation method suggested that other models that included additional parameters were less accurate than the primarily polling/previous performance based model that I chose – perhaps this would not be the case if I validated my models using a different election or used a more general form of cross-validation.
Quantitative tests
The first series of tests that I would run to evaluate my existing model would be to see if my state-level prediction errors are correlated with any of the variables that I used in my prediction model, as well as my model’s residuals. If any of the variables appear correlated with my prediction error, it could indicate that that variable may have been problematic to include. Furthermore, if my model’s residuals correlated with the state prediction error, it could indicate that there are notable variables that I omitted.
Second, I would test how changing the parameters of my model to include Republican polling values and lagged Republican vote share for the previous two elections when predicting Republican vote share would impact my results. If I find that my predictions of Republican vote share are more accurate when replacing mean_1_wk_poll_support, D_pv_lag1 and D_pv_lag2 with their Republican counterparts, this would lend credence to my hypothesis that it was problematic to use the same prediction variables for both predictions.
Finally, I would re-run my validation tests on the 32 models that I described in my last blog post, but use repetitive cross-validation instead of a single leave-one-out validation test. If the best performing model under this alternative form of validation more accurately predicted the outcome of the 2024 election, this could suggest that the average election (across either of the datasets that I would validate on, given the different training datasets that I considered) would better predict the 2024 election than the 2016 election. If this occurred, it could potentially lend credence to the argument that elections, on average, are more similar than I had perceived them to be. Alternatively, I could consider finding an election that is more similar to the 2024 Presidential Election than the 2016 Presidential Election and conducting leave-one-out validation on that other election. However, the changing dimension of time could make this challenging, especially if being used to predict future elections when we do not have the advantage of knowing how salient issues translate into voting outcomes.
Changes for next time
Moving forward, an easy fix that I would want to make would be to change the parameters of my Republican vote share prediction model to be more reflective of Republican predictors.
Beyond this, though, I would want to consider the results of the hypothesis tests above, as this would help determine the variables that I would include or exclude in my model, as well as the way I would compare variations of similar models. I strongly believe that I would add a variable for inflation, as this seems like a significant omitted variable, but I believe that adding other variables (or potentially other interaction terms) could substantially improve my model’s performance.
Beyond this, though, I would add some additional specifications to my model. For example, in order to avoid averaging across states that may be very different from each other, I would consider adding state fixed effects – a consideration that was brought up in our last class and section. Finally, I would consider using regularization methods other than LASSO, considering the discussion that my classmate Cathy brought up during a presentation of her model.
References
(1) Miller, Zeke, Michelle Price, Jill Colvin, and Will Weissert. 2024. “Donald Trump Elected 47th President of the United States | PBS News.” PBS News. November 6, 2024. https://www.pbs.org/newshour/politics/donald-trump-elected-47th-president-of-the-united-states. Reuters. 2024. “Trump’s U.S. Election Win: How World Leaders Reacted | Reuters.” Reuters. November 6, 2024. https://www.reuters.com/world/us/global-reaction-us-presidential-election-2024-11-06/. Rinaldi, Olivia, and Jacob Rosen. 2024. “Donald Trump Wins Election in Historic Comeback after 2020 Loss, Indictments and Bruising Campaign - CBS News.” CBS News. November 6, 2024. https://www.cbsnews.com/news/donald-trump-win-presidency-2024/.
(2) Dardet, Matthew. 2024. “Polling and ML Concepts.” Presented at the GOV 1347 Lab, September 18. Zou, Hui, and Trevor Hastie. 2005. “Regularization and Variable Selection Via the Elastic Net.” Journal of the Royal Statistical Society Series B: Statistical Methodology 67 (2): 301–20. https://doi.org/10.1111/j.1467-9868.2005.00503.x.
(3) Morris, G. Elliott. 2024. “Who Is Favored To Win The 2024 Presidential Election?” FiveThirtyEight. June 11, 2024. https://projects.fivethirtyeight.com/2024-election-forecast/.
(4) ABC News. n.d. “2024 US Presidential Election Results: Live Map.” ABC News. Accessed November 12, 2024. https://abcnews.go.com/Elections/2024-us-presidential-election-results-live-map/. akrun. 2020. “Answer to ‘How Do I Find Top 5 Values in a Data Frame Column?’” Stack Overflow. https://stackoverflow.com/a/63221153. The New York Times. 2024a. “Maine Second District Presidential Election Results,” November 5, 2024, sec. U.S. https://www.nytimes.com/interactive/2024/11/05/us/elections/results-maine-president-district-2.html. ———. 2024b. “Nebraska Second District Presidential Election Results,” November 5, 2024, sec. U.S. https://www.nytimes.com/interactive/2024/11/05/us/elections/results-nebraska-president-district-2.html.
(5) Build a data frame—Tibble. (n.d.). Retrieved November 17, 2024, from https://tibble.tidyverse.org/reference/tibble.html
(6) hadley. (2010, June 2). Answer to “How to move or position a legend in ggplot2” [Online post]. Stack Overflow. https://stackoverflow.com/a/2954610
(7) G, Ben. 2018. “Answer to ‘Left Join Only Selected Columns in R with the Merge() Function.’” Stack Overflow. https://stackoverflow.com/a/50746374.; hadley. (2010, June 2). Answer to “How to move or position a legend in ggplot2” [Online post]. Stack Overflow. https://stackoverflow.com/a/2954610
(8) Swenson, A. (2024, September 24). Several states are making late changes to election rules, even as voting is set to begin | AP News. AP News. https://apnews.com/article/election-2024-voting-ballots-certification-state-laws-c6d5a339503771596758a733851bfeae
(9) Lopez, G. (2024, November 8). How Inflation Shaped Voting. The New York Times. https://www.nytimes.com/2024/11/08/briefing/how-inflation-shaped-voting.html Zahn, M. (2024, November 8). Why inflation helped tip the election toward Trump, according to experts. ABC News. https://abcnews.go.com/Business/inflation-helped-tip-election-trump-experts/story?id=115601699; FRED Data from St. Louis FRED (appended with data from BEA and Brookings for 2024 GDP growth and Unemployment Figures, as discussed in previous blog post)
(10) Current US Inflation Rates: 2000-2024. (n.d.). Retrieved November 17, 2024, from https://www.usinflationcalculator.com/inflation/current-inflation-rates/
(11) Chiwaya, N., Kamisar, B., & Murphy, J. (2024, September 22). Presidential approval tracker: How popular is Joe Biden? NBC News. https://www.nbcnews.com/news/us-news/presidential-approval-tracker-how-popular-joe-biden-n1277509
(12) Wright, J. R. (2012). Unemployment and the Democratic Electoral Advantage. American Political Science Review, 106(4), 685–702. https://doi.org/10.1017/S0003055412000330 ; Lewis-Beck, M. S., & Stegmaier, M. (2000). Economic Determinants of Electoral Outcomes. Annual Review of Political Science, 3(1), 183–219. https://doi.org/10.1146/annurev.polisci.3.1.183 - While Wright and Lewis-Beck & Stegmaier discuss unemployment and electoral outcomes in this article, my inclusion of unemployment as a variable was largely based on my broader perception of unemployment as something that could be relevant to voters.
Data Sources
(Same sources as last blog, aside from the inclusion of ultimate popular vote outcomes)
All data sources are provided by GOV 1372 course staff
Popular Vote Datasets
National Popular Vote Data from Wikipedia, Abramowitz (2020), Abramowitz (2020) replication data, and manual changes
State Popular Vote Data from MIT elections project, Wikipedia, and manual editing
Additional data from Politico and Wall Street Journal for Maine and Nebraska District 2 added to test dataset to enable lagged predictions
2024 Popular Vote Totals by State
Economic Data
FRED Data from St. Louis FRED (appended with data from BEA and Brookings for 2024 GDP growth and Unemployment Figures)
Grants Data from Kriner and Reeves (2015) replication data
Polling Data
State Polls from FiveThirtyEight poll averages and preprocessing Elector Data
National Archives and Wikipedia, augmented with 2024 data for Nebraska and Maine districts from FiveThirtyEight Cost of Voting Index
Created by Michael Pomante II, but also generously facilitated by GOV 1372 course staff Turnout
Calculated from the Current Population Survey by Michael McDonald’s US Elections Project Data sources for Supreme Court cases are unknown, but were generously provided by the GOV 1372 course staff. However, I append the Supreme Court data with a metric of how the Supreme Court’s lean changed over time with data from Axios (Rubin, April. 2023. “Supreme Court Ideology Continues to Lean Conservative, New Data Shows.” Axios. July 3, 2023. https://www.axios.com/2023/07/03/supreme-court-justices-political-ideology-chart.