Although we discussed the impacts of electoral shocks in class this week, my blog post this week will focus on refining my model from last week. As I did last week, I will continue to compare two models, one using data from after 1984 and the other using data from after 1996.
I planned to make three initial changes this week. First, upon the recommendation of Matt Dardet, I took the log of grant allocation in order to see if my model predicted a significant effect. Second, after being inspired by my classmate Alex Heuss, I decided to measure the outcome of Democratic vote share, rather than two-party vote share, in order to better account for the disruptive ability of third-party candidates. Finally, I added confidence intervals to my measures, seeking to better estimate the precision of my predictions.
Update 1: Grant Allocation + Single Party Vote Share + Confidence Intervals
| Post 84 | Post 96 | |
|---|---|---|
| (Intercept) | −2.390 | −0.836 |
| (2.434) | (2.173) | |
| GDP_growth_quarterly | −0.327*** | −0.356*** |
| (0.044) | (0.039) | |
| mean_5_wk_poll_support | 0.962*** | 1.092*** |
| (0.030) | (0.031) | |
| turnout_lag1 | 0.008 | 0.019 |
| (0.029) | (0.027) | |
| unemployment | −0.576*** | −0.979*** |
| (0.159) | (0.156) | |
| log(total_grant) | 1.353*** | 0.694** |
| (0.229) | (0.243) | |
| Num.Obs. | 322 | 230 |
| R2 | 0.885 | 0.937 |
| R2 Adj. | 0.883 | 0.935 |
| AIC | 1666.9 | 1083.0 |
| BIC | 1693.3 | 1107.0 |
| Log.Lik. | −826.442 | −534.485 |
| F | 485.880 | 661.851 |
| RMSE | 3.15 | 2.47 |
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 |
Post 1984 Model:
| State | Predicted Winner | Democratic Vote Share | Low Pred | High Pred |
|---|---|---|---|---|
| Arizona | DEM | 52.22 | 51.17 | 53.26 |
| Georgia | DEM | 50.06 | 49.10 | 51.02 |
| Michigan | DEM | 52.23 | 51.13 | 53.34 |
| Nevada | DEM | 51.33 | 50.47 | 52.19 |
| North Carolina | DEM | 51.05 | 49.99 | 52.11 |
| Pennsylvania | DEM | 52.80 | 51.79 | 53.82 |
| Wisconsin | DEM | 51.98 | 50.81 | 53.16 |
Post 1996 Model:
| State | Predicted Winner | Democratic Vote Share | Low Pred | High Pred |
|---|---|---|---|---|
| Arizona | DEM | 52.87 | 51.77 | 53.97 |
| Georgia | DEM | 52.02 | 51.11 | 52.93 |
| Michigan | DEM | 53.72 | 52.63 | 54.82 |
| Nevada | DEM | 53.01 | 52.19 | 53.83 |
| North Carolina | DEM | 52.72 | 51.68 | 53.76 |
| Pennsylvania | DEM | 53.90 | 52.86 | 54.94 |
| Wisconsin | DEM | 53.88 | 52.73 | 55.04 |
By taking the log of grant allocation, we find a highly significant prediction value in the ultimate outcome. Furthermore, although the models still overwhelmingly appear to predict that the Democrats will win all of the battleground states, which seems relatively unlikely, these models show additional uncertainty, with the values for both Georgia and North Carolina falling within a range of uncertainty. To get an additional benchmark for the performance of both of these models, I also run out-of-sample cross validation
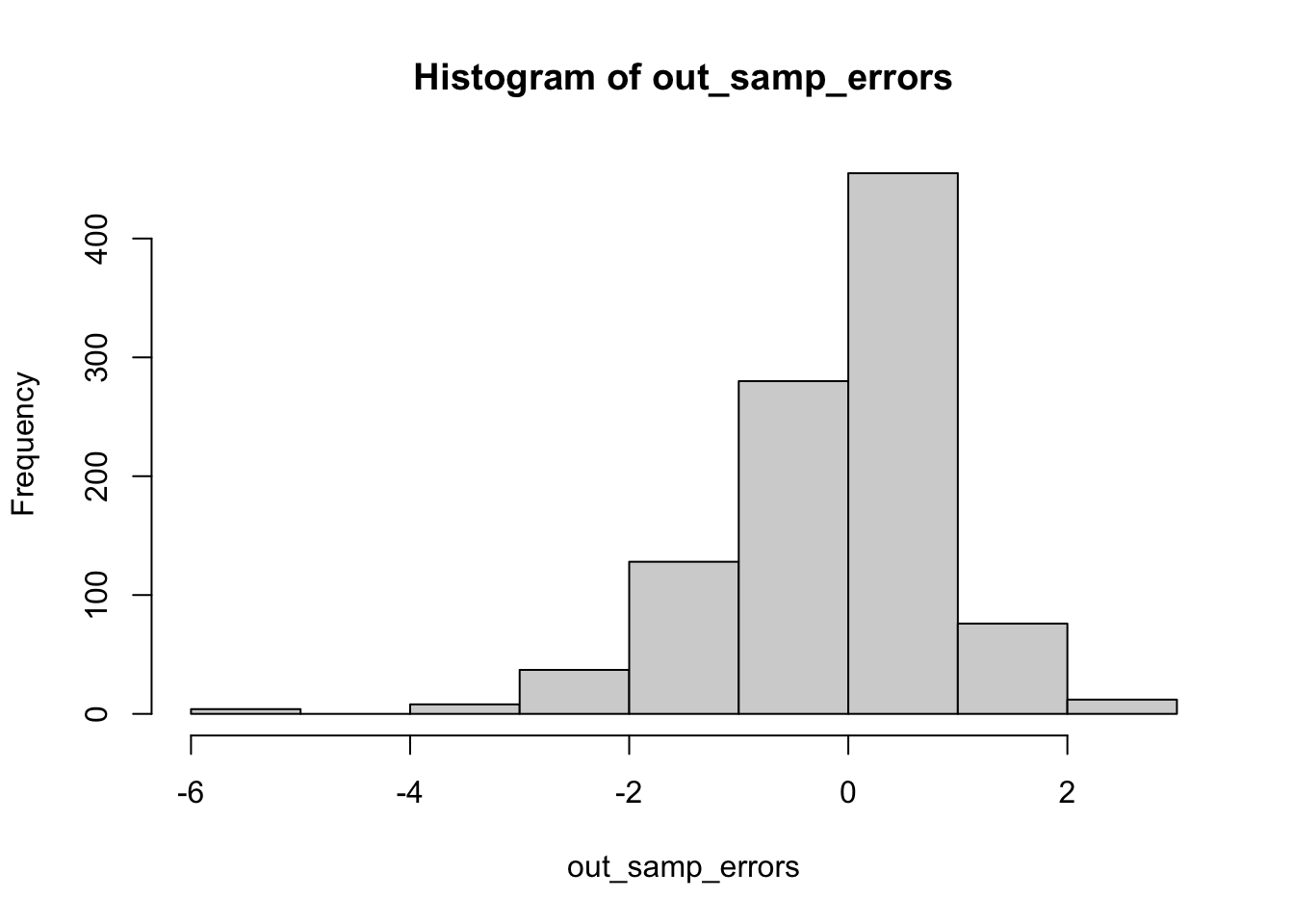
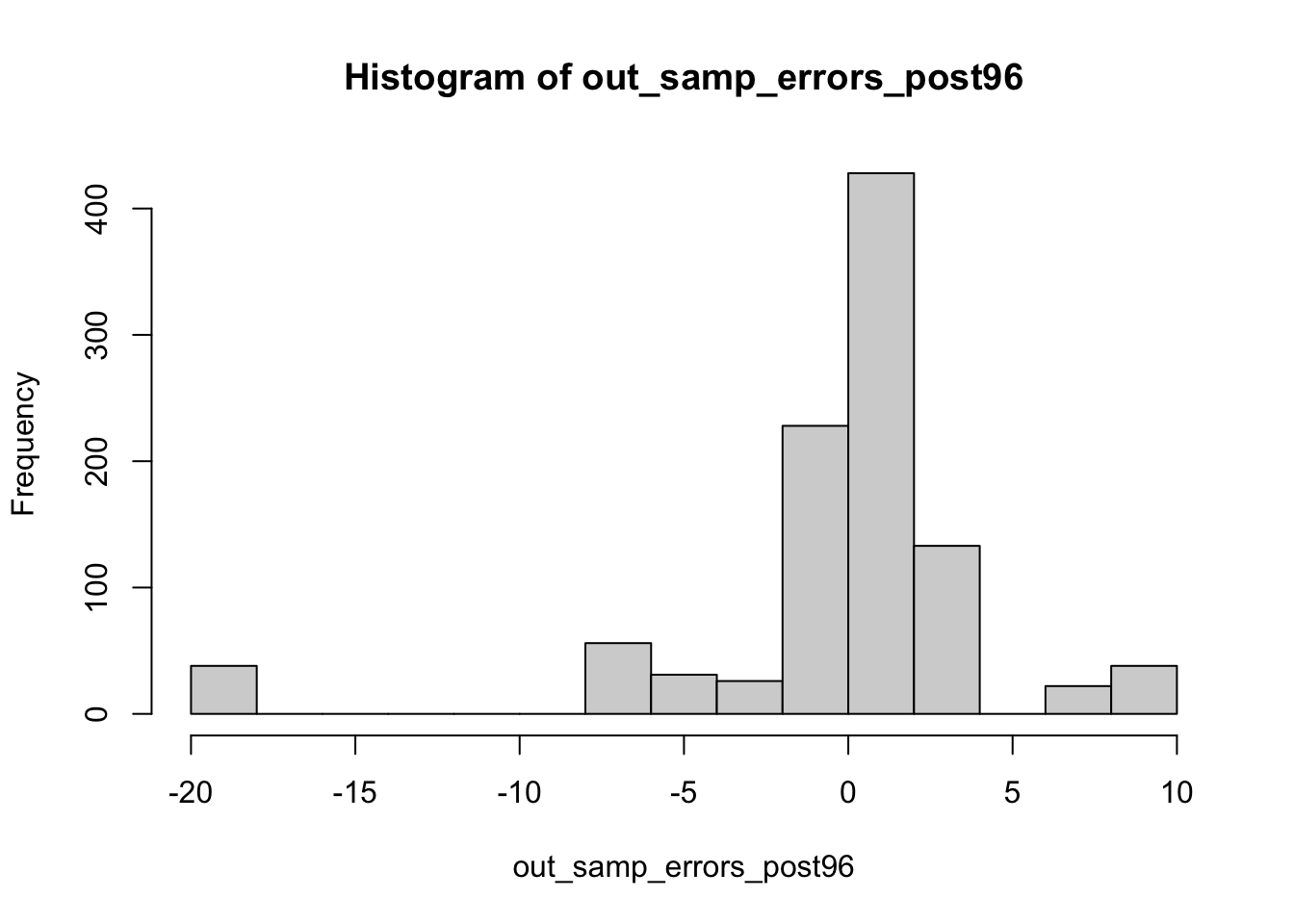
Though these results are slightly left skewed, we find a relatively small range of out-of-sample errors, especially for the post 84 model, and a high clustering around 0! This suggests that the post 84, especially, may be a strong predictor of out-of-sample outcomes.
To further improve my model, I was interested in including several additional metrics that we currently have access to, namely 1) Democratic vote share in the last election and 2) Democratic vote share in the second-last election. I anticipated that these metrics will add an estimation baseline to the predictions
Update 2: Adding Democratic Vote Share in Last Two Elections
| Post 84 | Post 96 | |
|---|---|---|
| (Intercept) | −3.550+ | −1.680 |
| (2.101) | (1.885) | |
| GDP_growth_quarterly | −0.271*** | −0.348*** |
| (0.038) | (0.035) | |
| mean_5_wk_poll_support | 0.744*** | 0.843*** |
| (0.034) | (0.039) | |
| turnout_lag1 | 0.008 | −0.006 |
| (0.025) | (0.024) | |
| unemployment | −0.477*** | −0.562*** |
| (0.139) | (0.144) | |
| log(total_grant) | 0.883*** | 0.290 |
| (0.202) | (0.215) | |
| D_pv_lag1 | 0.261*** | 0.241*** |
| (0.035) | (0.037) | |
| D_pv_lag2 | 0.040 | 0.052 |
| (0.033) | (0.033) | |
| Num.Obs. | 322 | 230 |
| R2 | 0.915 | 0.953 |
| R2 Adj. | 0.913 | 0.951 |
| AIC | 1572.2 | 1018.8 |
| BIC | 1606.2 | 1049.8 |
| Log.Lik. | −777.103 | −500.417 |
| F | 484.614 | 641.010 |
| RMSE | 2.70 | 2.13 |
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 |
When adding in these variables, we interestingly find that the R^2 value of both models is still incredibly high, suggesting that these models have high in-sample prediction ability. To see how well these models perform on out-of-sample data, I again conduct out-of-sample cross-validation.
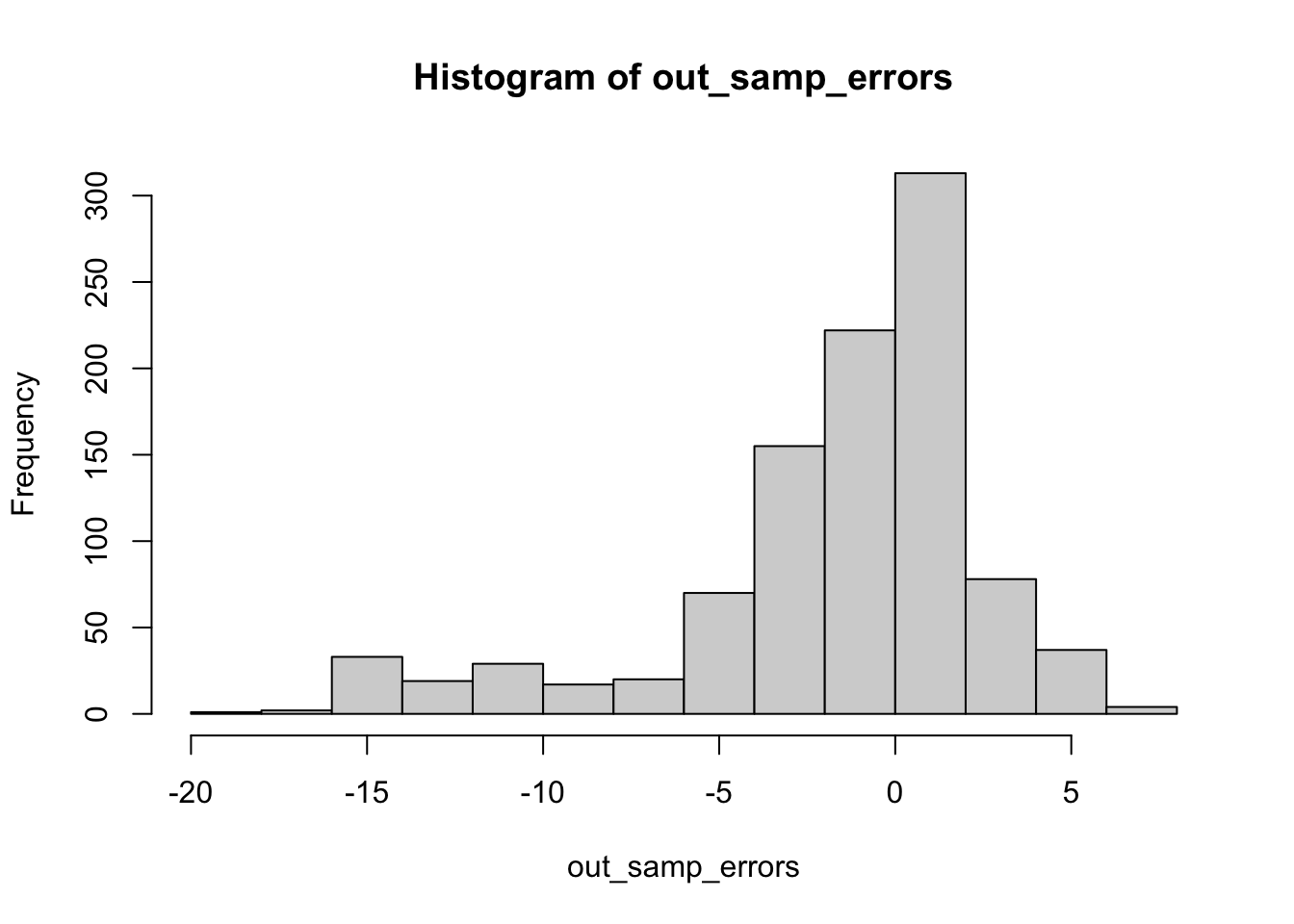
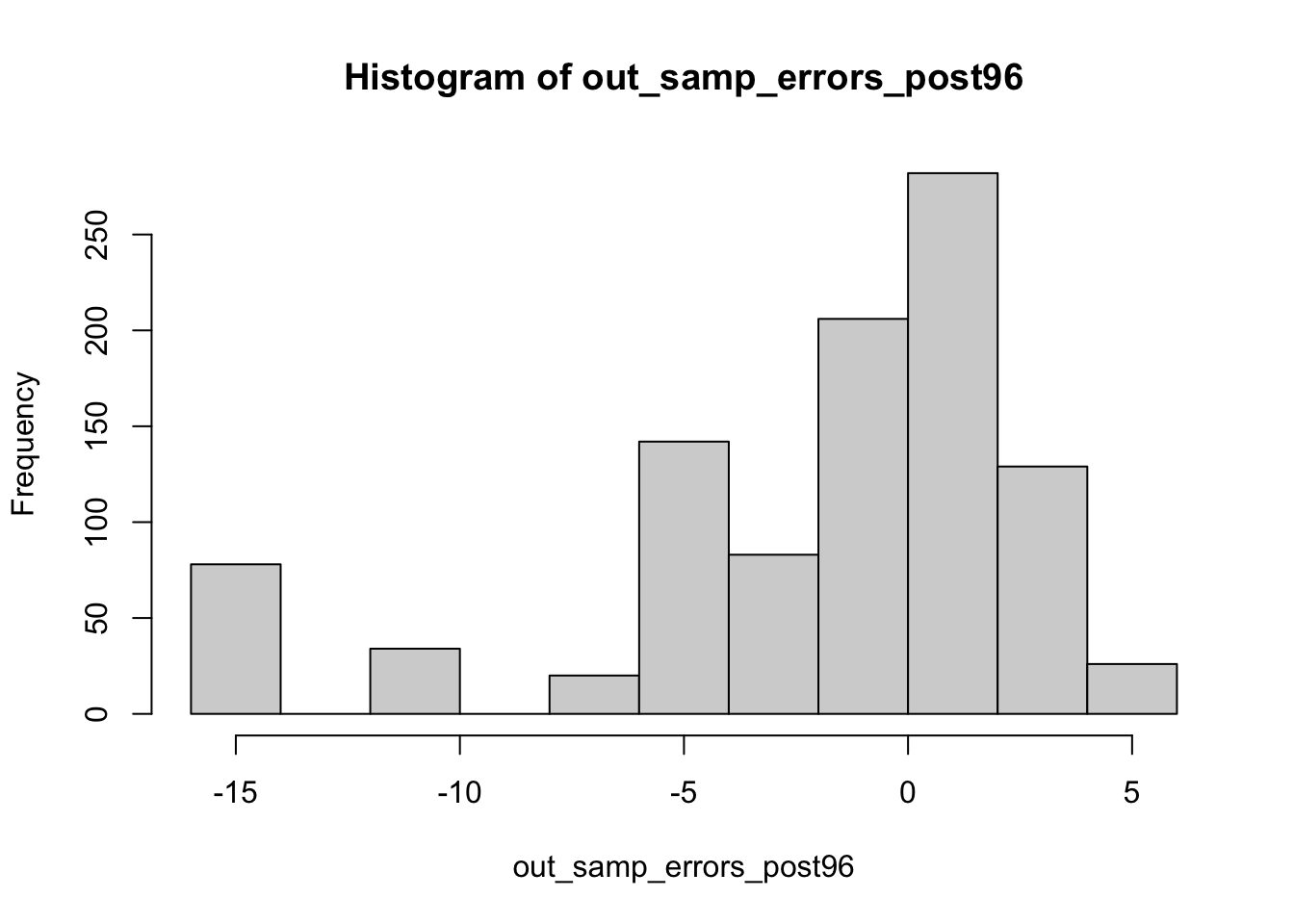
Unfortunately, it appears that these models are still left-skewed, but have more values that appear further away from zero. In general, it appears that these models are underpredicting Democratic vote share relative to the actual outcome. For reference, I also wanted to test how this would translate to 2024 prediction outcomes.
Post 1984 Model:
| State | Predicted Winner | Democratic Vote Share | Low Pred | High Pred |
|---|---|---|---|---|
| Arizona | DEM | 51.84 | 50.89 | 52.79 |
| Georgia | DEM | 50.53 | 49.63 | 51.42 |
| Michigan | DEM | 52.43 | 51.43 | 53.42 |
| Nevada | DEM | 51.67 | 50.90 | 52.44 |
| North Carolina | DEM | 51.00 | 50.05 | 51.95 |
| Pennsylvania | DEM | 52.64 | 51.74 | 53.54 |
| Wisconsin | DEM | 51.98 | 50.93 | 53.04 |
Post 1996 Model:
| State | Predicted Winner | Democratic Vote Share | Low Pred | High Pred |
|---|---|---|---|---|
| Arizona | DEM | 50.96 | 49.88 | 52.04 |
| Georgia | DEM | 50.83 | 49.97 | 51.69 |
| Michigan | DEM | 52.16 | 51.13 | 53.20 |
| Nevada | DEM | 51.78 | 51.01 | 52.54 |
| North Carolina | DEM | 50.96 | 49.96 | 51.96 |
| Pennsylvania | DEM | 52.13 | 51.13 | 53.12 |
| Wisconsin | DEM | 52.05 | 50.95 | 53.15 |
Despite this greater skew, we do not see a substantive shift in outcomes, with a Democratic sweep still being predicted. However, it is interesting to note that the post 96 model appears to predict a more conservative Democratic vote share given these specifications, with the Arizona, Georgia, and North Carolina models all predicting uncertain outcomes.
In addition to altering the variables in my model, I wanted to explore if changing their form would add additional precision. To inform this decision, I plotted the relationship between Democratic vote share and each of the explanatory models that I had included in my prediction, aside from federal funding allocation.
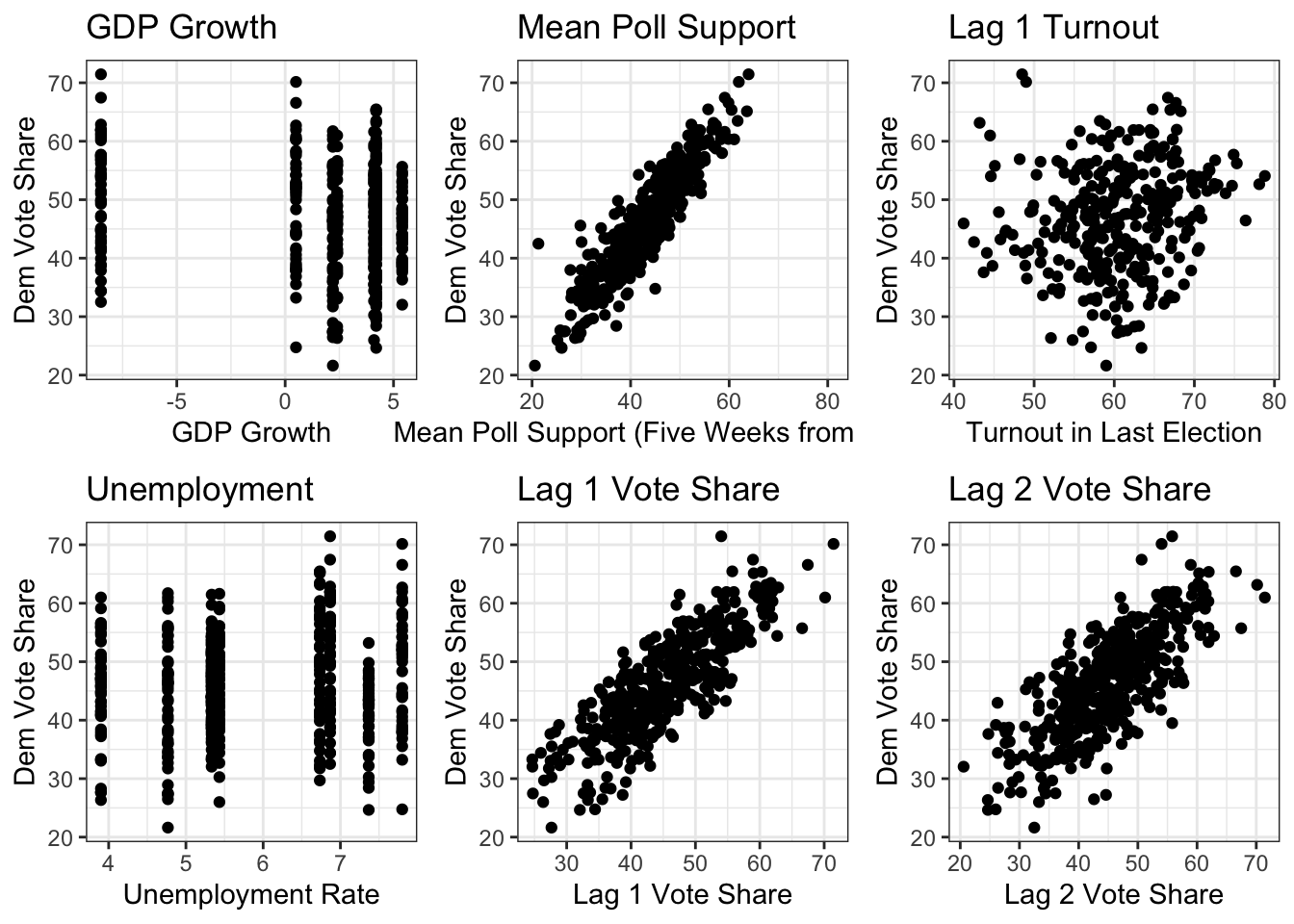
From these graphs, we can confirm that lagged vote share from the prior two elections and mean poll support are strongly linearly related to our predicted outcome. This suggests that a it might not be necessary to alter the functional form of these variables in our model. However, it appears that the impact of GDP growth, unemployment rate, and turnout in the last election have a rather ambiguous effect.
Out of curiosity, I wanted to how much the results would vary if I only included the three highly predictive variables identified here in my prediction models. I run this analysis below.
Update 3: Only Poll Support and Vote Share in Last Two Elections
| Post 84 | Post 96 | |
|---|---|---|
| (Intercept) | −2.185* | −3.538*** |
| (0.889) | (0.883) | |
| mean_5_wk_poll_support | 0.745*** | 0.820*** |
| (0.030) | (0.035) | |
| D_pv_lag1 | 0.324*** | 0.358*** |
| (0.032) | (0.037) | |
| D_pv_lag2 | 0.036 | −0.044 |
| (0.031) | (0.035) | |
| Num.Obs. | 434 | 290 |
| R2 | 0.878 | 0.928 |
| R2 Adj. | 0.878 | 0.927 |
| AIC | 2208.5 | 1379.3 |
| BIC | 2228.8 | 1397.6 |
| Log.Lik. | −1099.240 | −684.649 |
| F | 1035.486 | 1221.381 |
| RMSE | 3.05 | 2.56 |
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 |
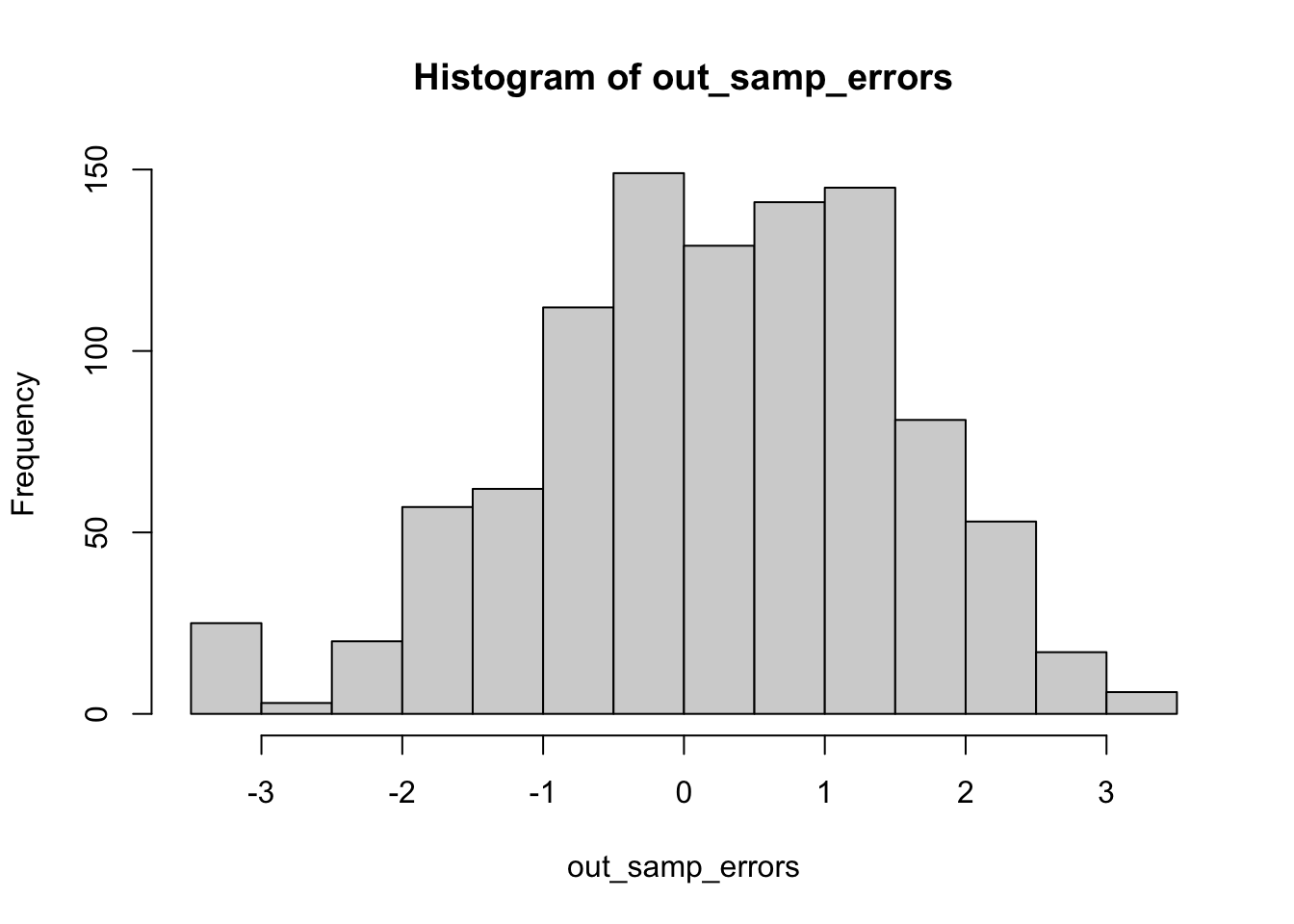
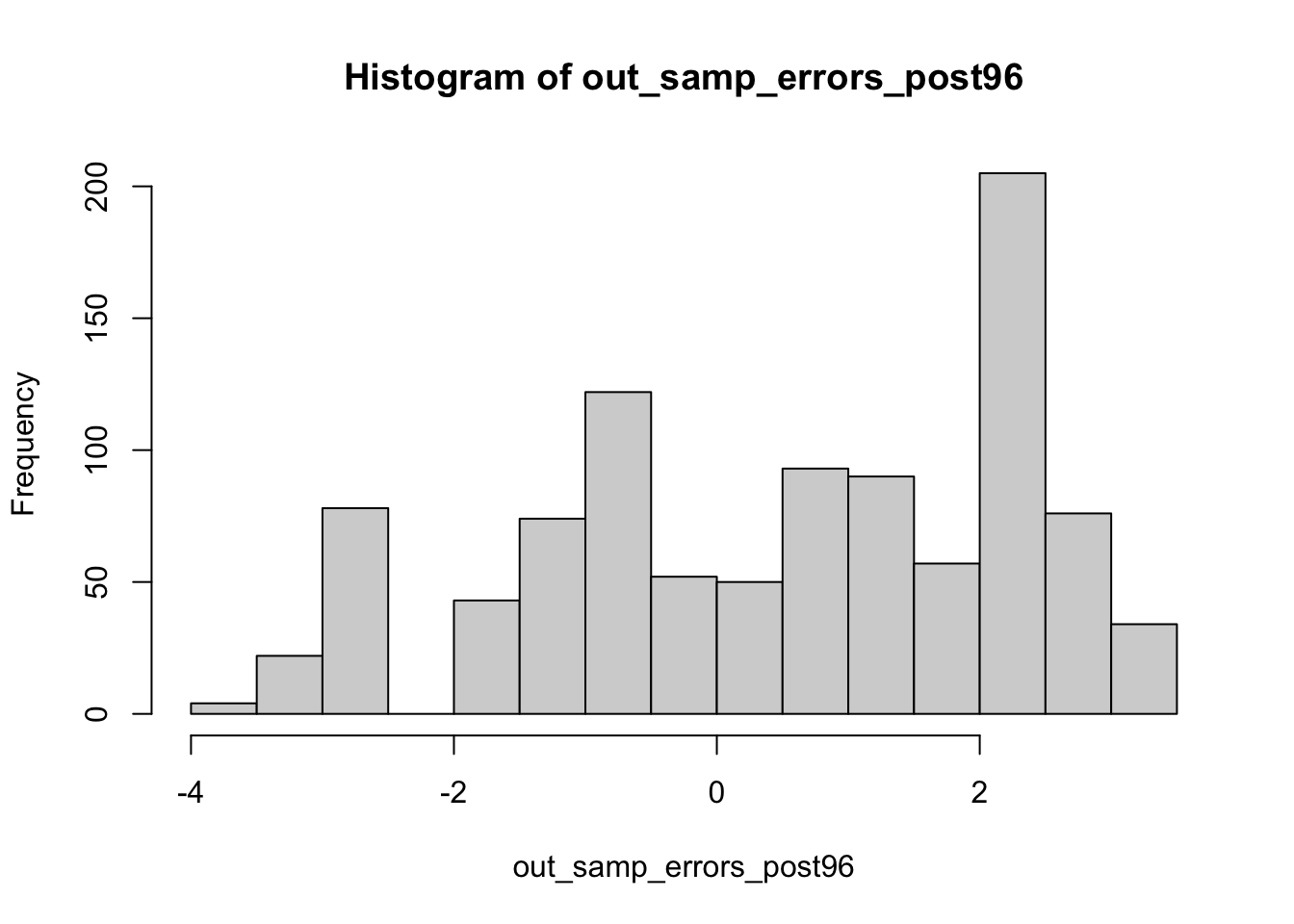
While both of these models have relatively high in-sample fit, they both interestingly have a much smaller range of out-of-sample errors than our previous models. The post-84 model appears especially strong in this metric, with a histogram of out-of-sample errors centered around zero. Though the spread of the out-of-sample errors appears quite large, this is likely because the error measures are relatively small, therefore not detracting from this model’s strength. I again explored how this would translate to predictions.
Post 1984 Model:
| State | Predicted Winner | Democratic Vote Share | Low Pred | High Pred |
|---|---|---|---|---|
| Arizona | DEM | 51.84 | 49.95 | 50.71 |
| Georgia | DEM | 50.53 | 50.33 | 51.08 |
| Michigan | DEM | 52.43 | 51.40 | 52.15 |
| Nevada | DEM | 51.67 | 51.09 | 51.79 |
| North Carolina | DEM | 51.00 | 50.24 | 50.95 |
| Pennsylvania | DEM | 52.64 | 51.16 | 51.87 |
| Wisconsin | DEM | 51.98 | 51.31 | 52.08 |
| Interestingly, despite this additional precision, we find a greater certainty of a Democratic sweep, with only Arizona having uncertain results. |
Next, given the argument made by Shaw and Petrocik (5), and also addressed by Matt Dardet, that turnout does not predict party-specific outcomes, I was interested in seeing how my models would perform without the lagged turnout variable.
Update 4: Removing Lagged Turnout
| Post 84 | Post 96 | |
|---|---|---|
| (Intercept) | −2.836* | −2.561* |
| (1.350) | (1.221) | |
| GDP_growth_quarterly | −0.236*** | −0.330*** |
| (0.036) | (0.033) | |
| mean_5_wk_poll_support | 0.726*** | 0.830*** |
| (0.030) | (0.036) | |
| unemployment | −0.396** | −0.538*** |
| (0.121) | (0.122) | |
| log(total_grant) | 0.869*** | 0.419* |
| (0.180) | (0.192) | |
| D_pv_lag1 | 0.273*** | 0.276*** |
| (0.031) | (0.035) | |
| D_pv_lag2 | 0.032 | 0.016 |
| (0.029) | (0.030) | |
| Num.Obs. | 434 | 290 |
| R2 | 0.894 | 0.948 |
| R2 Adj. | 0.893 | 0.946 |
| AIC | 2153.3 | 1291.6 |
| BIC | 2185.9 | 1321.0 |
| Log.Lik. | −1068.664 | −637.809 |
| F | 602.696 | 852.690 |
| RMSE | 2.84 | 2.18 |
| + p < 0.1, * p < 0.05, ** p < 0.01, *** p < 0.001 |
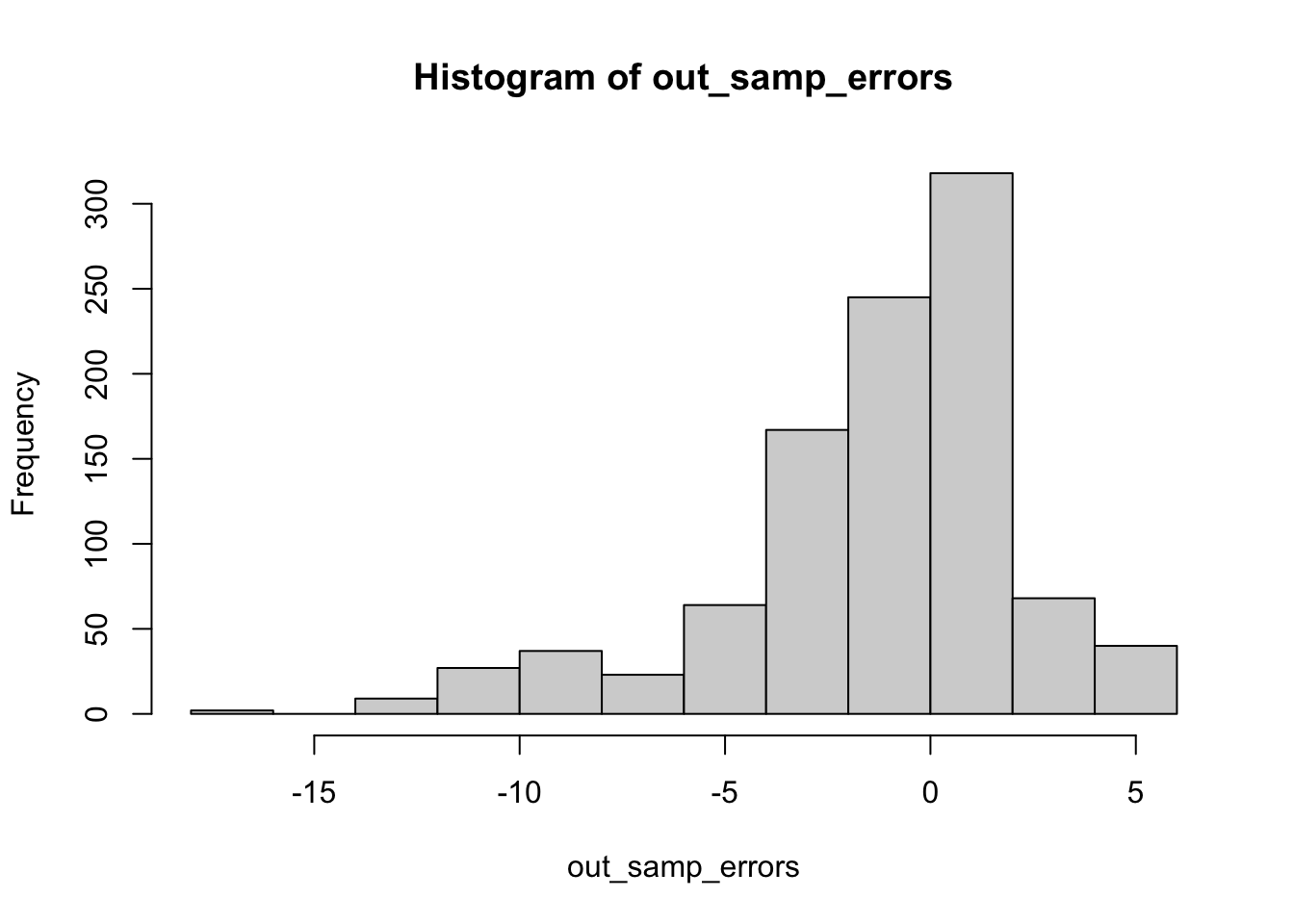
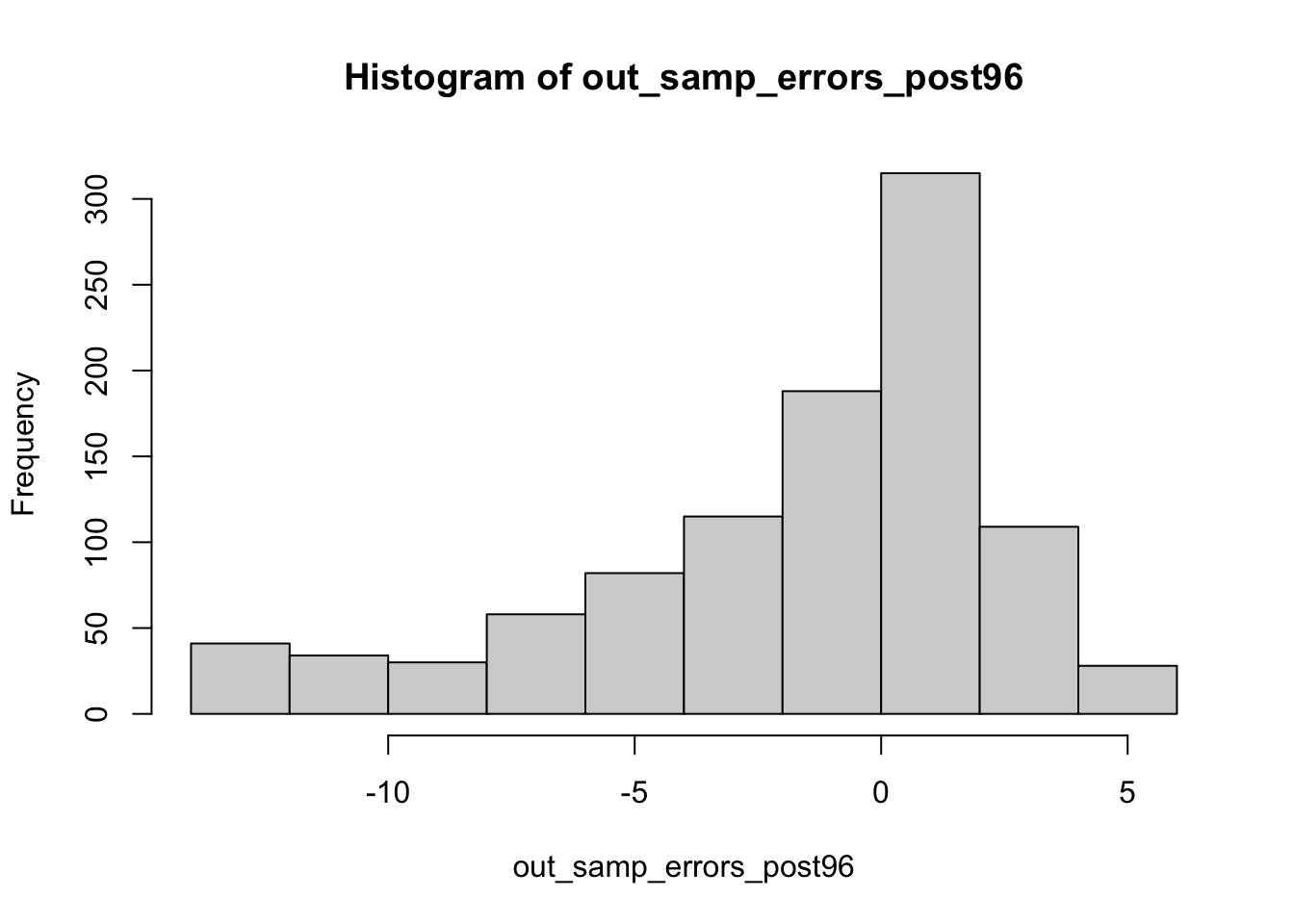
Somewhat aligning with Shaw and Petrocik’s argument, the out-of-sample error range appears to be slightly smaller than when turnout was included. However, these errors are still significantly larger than when only the three strongly predictive variables were included. Again, I include election predictions for reference.
Post 1984 Model:
| State | Predicted Winner | Democratic Vote Share | Low Pred | High Pred |
|---|---|---|---|---|
| Arizona | DEM | 50.33 | 50.54 | 52.06 |
| Georgia | DEM | 50.70 | 50.27 | 51.53 |
| Michigan | DEM | 51.78 | 51.77 | 52.94 |
| Nevada | DEM | 51.44 | 51.25 | 52.40 |
| North Carolina | DEM | 50.60 | 50.47 | 51.67 |
| Pennsylvania | DEM | 51.51 | 51.68 | 52.97 |
| Wisconsin | DEM | 51.69 | 51.54 | 52.80 |
Post 1996 Model:
| State | Predicted Winner | Democratic Vote Share | Low Pred | High Pred |
|---|---|---|---|---|
| Arizona | DEM | 51.30 | 50.54 | 52.06 |
| Georgia | DEM | 50.90 | 50.27 | 51.53 |
| Michigan | DEM | 52.36 | 51.77 | 52.94 |
| Nevada | DEM | 51.82 | 51.25 | 52.40 |
| North Carolina | DEM | 51.07 | 50.47 | 51.67 |
| Pennsylvania | DEM | 52.32 | 51.68 | 52.97 |
| Wisconsin | DEM | 52.17 | 51.54 | 52.80 |
These results continue to show a Democratic sweep, with more certainty than most of the previous models (other than the first post-96 model)
Moving forward, there are a few additional steps I would like to take. First, I would like to incorporate the Supreme Court precedent data that I modified to include whether or not the shifts were accompanied by a conservative shift in the “median justice” of the court, as described by Rubin in Axios (5). In particular, I would like to evaluate the effect of an interaction term between precedent changes and the court’s ideological shifts. However, following this, I am interested in running these models, especially the models that include more than the three highly predictive variables, through Elastic Net in order to engage in feature selection and select my final model.
## Additional code added after Week 8 submission to save final data
write.csv(test, "test_1.csv", row.names = FALSE)
write.csv(train_post84, "train84_1.csv", row.names = FALSE)
write.csv(train_post96, "train96_1.csv", row.names = FALSE)
References
- Julia. 2020. “Answer to ‘Export R Data to Csv.’” Stack Overflow. https://stackoverflow.com/a/62017887.; Bobbitt, Zach. 2023. “How to Convert Datetime to Date in R.” Statology. January 25, 2023. https://www.statology.org/r-convert-datetime-to-date/. GKi. 2023. “Answer to ‘Extract Month and Year From Date in R.’” Stack Overflow. https://stackoverflow.com/a/76709941. rafa.pereira. 2016. “Answer to ‘Extract Month and Year From Date in R.’” Stack Overflow. https://stackoverflow.com/a/37704385.; “Extract the Last N Characters from String in R - Spark By {Examples}.” n.d. Accessed October 26, 2024. https://sparkbyexamples.com/r-programming/extract-the-last-n-characters-from-string-in-r/.; Rubin, April. 2023. “Supreme Court Ideology Continues to Lean Conservative, New Data Shows.” Axios. July 3, 2023. https://www.axios.com/2023/07/03/supreme-court-justices-political-ideology-chart.
- Andina, Matias. 2016. “Answer to ‘How to Remove $ and % from Columns in R?’” Stack Overflow. https://stackoverflow.com/a/35757945.; camille. 2022. “Answer to ‘Convert Column Names to Title Case.’” Stack Overflow. https://stackoverflow.com/a/70804865.
- Andina, Matias. 2016. “Answer to ‘How to Remove $ and % from Columns in R?’” Stack Overflow. https://stackoverflow.com/a/35757945. “RPubs - Linear Regression Confidence and Prediction Intervals.” n.d. Accessed October 26, 2024. https://rpubs.com/aaronsc32/regression-confidence-prediction-intervals.
- “How to Replace Values in R with Examples - Spark By {Examples}.” n.d. Accessed October 26, 2024. https://sparkbyexamples.com/r-programming/replace-values-in-r/. camille. 2022. “Answer to ‘Convert Column Names to Title Case.’” Stack Overflow. https://stackoverflow.com/a/70804865.
- Rubin, April. 2023. “Supreme Court Ideology Continues to Lean Conservative, New Data Shows.” Axios. July 3, 2023. https://www.axios.com/2023/07/03/supreme-court-justices-political-ideology-chart.
Data Sources
All data sources are provided by GOV 1372 course staff
Popular Vote Datasets
National Popular Vote Data from Wikipedia, Abramowitz (2020), Abramowitz (2020) replication data, and manual changes
State Popular Vote Data from MIT elections project, Wikipedia, and manual editing
Economic Data
FRED Data from St. Louis FRED
Grants Data from Kriner and Reeves (2015) replication data
Polling Data
- State Polls from FiveThirtyEight poll averages and preprocessing
Data sources for state and county-level turnout, protests, and Supreme Court cases are unknown, but were generously provided by the GOV 1372 course staff. However, I append the Supreme Court data with a metric of how the Supreme Court’s leaninted over time with data from Axios (Rubin, April. 2023. “Supreme Court Ideology Continues to Lean Conservative, New Data Shows.” Axios. July 3, 2023. https://www.axios.com/2023/07/03/supreme-court-justices-political-ideology-chart. )